[Tech] Side Channel Attacks
Side channel Attacks
Steal Secret through side channels
side channels: timing; power; em emissions; sound; heat; cache
Infer secrets via secret-dependent physical information
Example
RSA Decryption Algorithm
1 | for bit in k: |
Timing side channel
1 | if (k == 1) then |
Break RSA with Timing Side Channel
Break RSA with Power Side channel
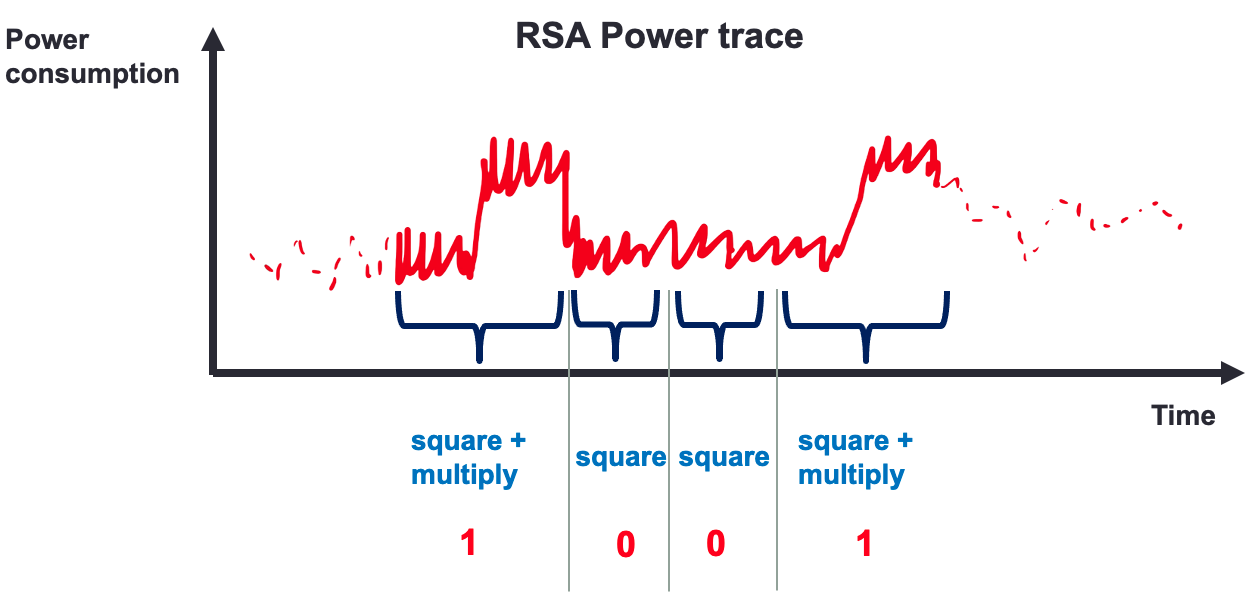
Break RSA with Power Side channel

Cache-based side channel
Cache lines: minimal storage units of a cache 64 bytes
Cache sets: equal number of cache lines
1 | // Table Lookup |
idx is virtual address, for L1 and L2 cache, virtual address is used for indexing, however for L3 cache, physical address is used.
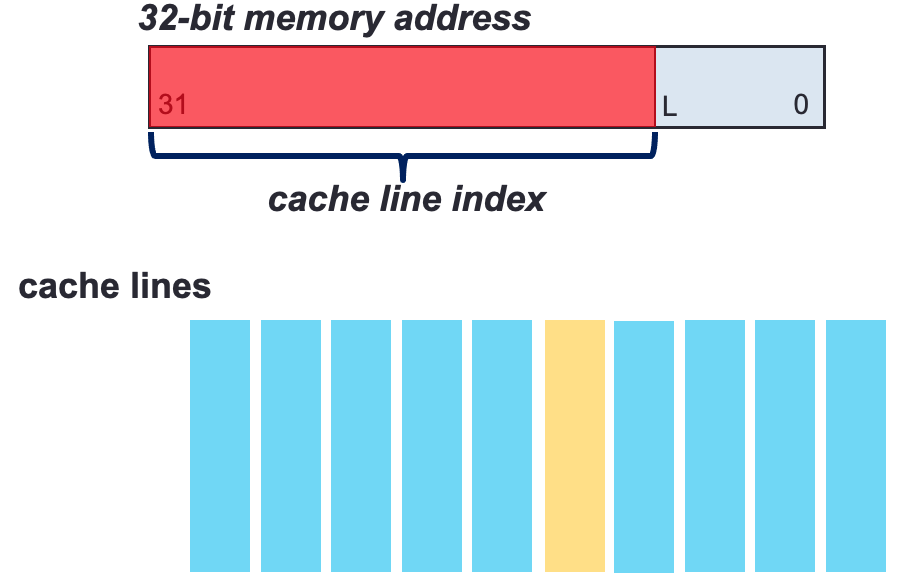
The upper part of a memory address maps a memory access to a cache line access
Set index: locate the set in which the data may be stored.
Tag: confirm the data is present in one of its lines
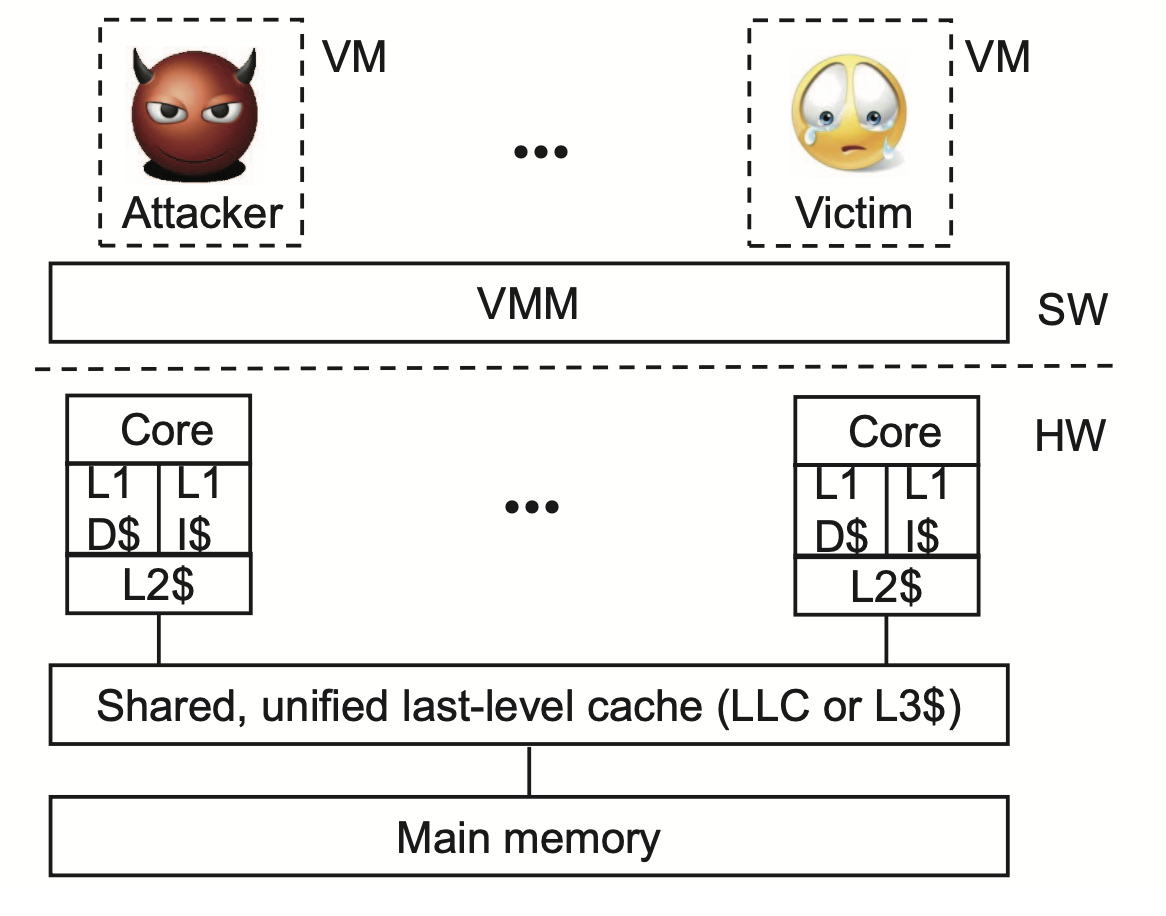
The System model for a multi-core processor, L1 and L2 cache is private to each core and LLC is shared across multiple cores;
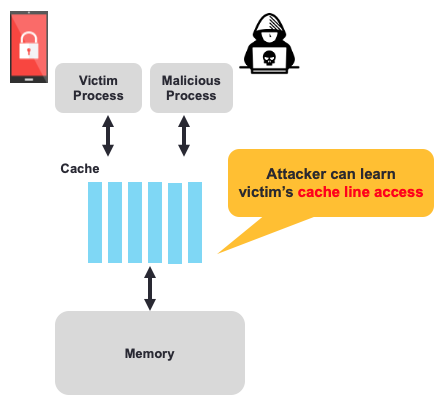
Threat model
Support
Meltdown
Spectre
L1 and L2 Cache Side Channel
Prime-and-Probe
LLC Side Channel
Branch Prediction
Branch prediction is one of the most important features of modern pipelined processors. At a high level, an instruction pipeline consists of four major stages: fetch, decode, execute, and write-back. At any given time, there are a number of instructions in-flight in the pipeline. Pro- cessors exploit instruction-level parallelism and out-of-order execution to maximize the throughput while still maintaining in-order retirement of instructions. Branch instructions can severely reduce instruction throughput since the processor cannot execute past the branch until the branch’s target and outcome are determined. Unless mitigated, branches would lead to pipeline stalls, also known as bubbles. Hence, modern processors use a branch prediction unit (BPU) to predict branch outcomes and branch targets. While the BPU increases throughput in general, it is worth noting that in the case of a misprediction, there is a pretty high penalty because the processor needs to clear the pipeline and roll back any speculative execution results. This is why Intel provides a dedicated hardware feature (the LBR) to profile branch execution
Branch and branch target prediction. Branch prediction is a procedure to predict the next instruction of a conditional branch by guessing whether it will be taken. Branch target prediction is a procedure to predict and fetch the target instruction of a branch before executing it. For branch target prediction, modern processors have the BTB to store the computed target addresses of taken branch instructions and fetch them when the corresponding branch instructions are predicted as taken.
BTB structure and partial tag hit. The BTB is an associative structure that resembles a cache. Address bits are used to compute the set index and tag fields. The number of bits used for set index is determined by the size of the BTB. Unlike a cache that uses all the remaining address bits for the tag, the BTB uses a subset of the remaining bits for the tag (i.e., a partial tag). For example, in a 64-bit address space, if ADDR[11:0] is used for index, instead of using ADDR[63:12] for a tag, only a partial number of bits such as ADDR[31:12] is used as the tag. The reasons for this choice are as follows: First, compared to a data cache, the BTB’s size is very small, and the overhead of complete tags can be very high. Second, the higher-order bits typically tend to be the same within a program. Third, unlike a cache, which needs to maintain an accurate microarchitectural state, the BTB is just a predictor. Even if a partial tag hit results in a false BTB hit, the correct target will be computed at the execution stage and the pipeline will roll back if the prediction is wrong (i.e., it affects only performance, not correctness.)
Static and dynamic branch prediction. Static branch prediction is a default rule for predicting the next instruction after a branch instruction when there is no history. First, the processor predicts that a forward conditional branch—a conditional branch whose target address is higher than itself—will not be taken, which means the next instruction will be directly fetched (i.e., a fall-through path). Second, the processor predicts that a backward conditional branch—a conditional branch whose target address is lower than itself—will be taken; that is, the specified target will be fetched. Third, the processor predicts that an indirect branch will not be taken, similar to the forward conditional branch case. Fourth, the processor predicts that an unconditional branch will be taken, similar to the backward conditional branch case. In contrast, when a branch has a history in the BTB, the processor will predict the next instruction according to the history. This procedure is known as dynamic branch prediction.