Memory Safety
1. ASAN
https://juejin.cn/post/6844904111570157575
https://www.ndss-symposium.org/wp-content/uploads/2018/02/ndss2018_05A-5_Han_paper.pdf
Given the following C++ program test.cpp
1 |
|

1. ASan工作原理
https://github.com/google/sanitizers/wiki/AddressSanitizerAlgorithm
ASAN工具包含两大块:
- 插桩模块(Instrumentation module)
- 一个运行时库(Runtime library)
插桩模块主要会做两件事:(静态插桩,需重新编译)
- 为每个程序中用到的内存地址都开辟shadow memory来存储内存的相应状态
- 对所有的memory access都去检查该内存所对应的shadow memory的状态
- 开辟shadow memory的shadow memory为bad region
- 为所有栈上对象和全局对象创建前后的保护区(Poisoned redzone),为检测溢出做准备。
运行时库也同样会做两件事:
- hook malloc函数,为所有堆对象创建前后的保护区
- hook free函数,将free掉的堆区域隔离(quarantine)一段时间,避免它立即被分配给其他人使用
- 对错误情况进行输出,包括堆栈信息
2. Shadow Memory
Shadow memory是内存中的一块区域,其中的数据仅仅反应其他正常内存的状态信息,可以理解为正常内存的元数据,而正常内存中存储的才是程序真正需要的数据。
Malloc函数返回的地址通常是8字节对齐的,因此任意一个由(对齐的)8字节所组成的内存区域必然落在以下9种状态之中:最前面的k(0≤k≤8)字节是可寻址的,而剩下的8-k字节是不可寻址的。这9种状态便可以用shadow memory中的一个字节来进行编码。
实际上,一个byte可以编码的状态总共有256(2^8)种,因此用在这里绰绰有余。
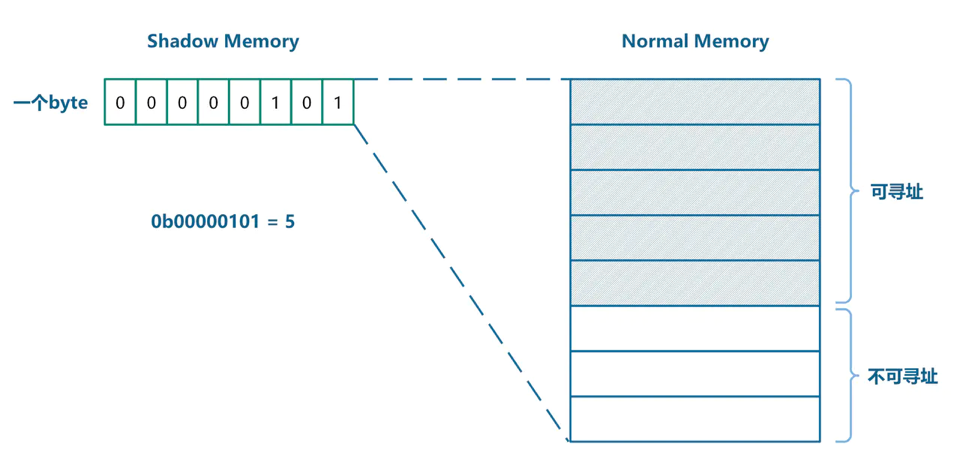
Shadow memory和normal memory的映射关系如上图所示。一个byte的shadow memory反映8个byte normal memory的状态。如何根据normal memory的地址找到它对应的shadow memory呢?
对于64位机器上的Android而言,二者的转换公式如下:
Shadow memory address = (Normal memory address >> 3) + 0x7fff8000 (for 64 bit)
Shadow memory address = (Normal memory address >> 3) + 0x20000000 (for 32 bit)
右移三位的目的是为了完成8=>1的映射,而加一个offset是为了和Normal memory区分开来。最终内存空间种会存在如下的映射关系:
Bad代表的是shadow memory的shadow memory,因此其中数据没有意义,该内存区域不可使用。shadown内存的值有以下几种:
- 8个字节都可寻址,shadow memory的值为0
- 负数:所有byte都无效,全无效一般都是插入的内存,并且每种插入的内存对应的负数值不同
- k:表示前k个byte是有效,后8-k个无效,前提:malloc返回的地址内存对齐
为什么0个字节可寻址的情况shadow memory不为0,而是负数呢?是因为0个字节可寻址其实可以继续分为多种情况,譬如:
- 这块区域是heap redzones
- 这块区域是stack redzones
- 这块区域是global redzones
- 这块区域是freed memory
对所有0个字节可寻址的normal memory region的访问都是非法的,ASAN将会报错。而根据其shadow memory的值便可以具体判断是哪一种错。
1 | Shadow byte legend (one shadow byte represents 8 application bytes): |
3. ASan 检验算法
1 | ShadowAddr = (Addr >> 3) + Offset; // map from normal memory region to shadow memory |
在每次内存访问时,都会执行如上的伪代码,以判断此次内存访问是否合规。
首先根据normal memory的地址找到对应shadow memory的地址,然后取出其中存取的byte值:k。
- k!=0,说明Normal memory region中的8个字节并不是都可以被寻址的。
- Addr & 7,将得知此次内存访问是从memory region的第几个byte开始的。
- AccessSize是此次内存访问需要访问的字节长度。
- (Addr&7)+AccessSize > k,则说明此次内存访问将会访问到不可寻址的字节。(具体可分为k大于0和小于0两种情况来分析)
当此次内存访问可能会访问到不可寻址的字节时,ASAN会报错并结合shadow memory中具体的值明确错误类型。
1 | // before instrumentation |
检验算法的汇编举例如下:
1 | # int load4(int *a) { return *a; } |
4. ASAN代码解释
对于下列C++代码
1 |
|
其LLVM的代码本来为
1 | define dso_local i32 @main(i32 %argc, i8** %argv) #0 !dbg !9 { |
其中有a[5]和a[argc]两个内存访问,针对这两个内存访问,Memory Sanitizer分别加入如下语句进行检查
1 | ; a[5] |
%arrayidx指的是指向a[5]的指针,memory
sanitizer会检查这个指针指向的内存区域是不是合法的。首先将其扩展成64位后左移3个bit后加上offset
2147450880(0x7FFF8000),也就是%5,该值为对应的shadow
memory的内存地址,从shadow memory中加载内存信息为%7:
- 首先判断该信息是否为0,如果等于0,表示8个内存区域都可以访问,跳转到block
15,说明可以利用
%arrayidx访问相应数据 - 如果不等于0,判断可访问的字节数是否合法,即是否大于k,若大于则跳转到block 14,报错。
1 | ShadowAddr = (Addr >> 3) + Offset; // map from normal memory region to shadow memory |
同样的%arrayidx1指的是指向a[argc]的指针,memory
sanitizer会检查这个指针指向的内存区域是不是合法。
1 | %arrayidx1 = getelementptr inbounds i32, i32* %16, i64 %idxprom, !dbg !19 |
5. 缺陷
- CPU和Memory资源的消耗
- UseAfterFree的检测依赖隔离区,而隔离时间是非永久的,跨越过隔离时间后再次访问是有限的,会导致漏检。
- Overflow的检测依赖安全区,而安全区是有大小的,大小是有限的,跨越安全区访问就有可能也不报错,这是另一个漏检的原因。
HWASAN
1. 什么是HWASAN
HWASAN是ASAN工具的升级版,它基本上解决了上面所说的ASAN的3个问题。但是它需要64位硬件的支持,也就是说在32位的机器上该工具无法运行。
AArch64是64位的架构,指的是寄存器的宽度是64位,但并不表示内存的寻址范围是2^64。真实的寻址范围和处理器内部的总线宽度有关,实际上ARMv8寻址只用到了低48位。也就是说,一个64bit的指针值,其中真正用于寻址的只有低48位。那么剩下的高16位干什么用呢?答案是随意发挥。AArch64拥有地址标记(Address tagging, or top-byte-ignore)的特性,它表示允许软件使用64bit指针值的高8位开发特定功能。
HWASAN用这8bit来存储一块内存区域的标签(tag)。接下来我们以堆内存示例,展示这8bit到底如何起作用。
堆内存通过malloc分配出来,HWASAN在它返回地址时会更改该有效地址的高8位。更改的值是一个随机生成的单字节值,譬如0xaf。此外,该分配出来的内存对应的shadow memory值也设为0xaf。需要注意的是,HWASAN中normal memory和shadow memory的映射关系是16➡1,而ASAN中二者的映射关系是8➡1
2. 检测UseAfterFree
2.1 Use-After-Free
当一个堆内存被分配出来时,返回给用户空间的地址便已经带上了标签(存储于地址的高8位)。之后通过该地址进行内存访问,将先检测地址中的标签值和访问地址对应的shadow memory的值是否相等。如果相等则验证通过,可以进行正常的内存访问。
当该内存被free时,HWASAN会为该块区域分配一个新的随机值,存储于其对应的shadow memory中。如果此后再有新的访问,则地址中的标签值必然不等于shadow memory中存储的新的随机值,因此会有错误产生。通过如下图示可以很好地明白这一点(图中只用了4bit记录标记值,但不影响理解,8bit标记值的检测和它一致)。
2.2 Heap-Over-Flow
想要检测HeapOverFlow,有一个前提需要满足:相邻的memory区域需要有不同的shadow memory值,否则将无法分辨两个不同的memory区域。为每个memory区域随机分配将有概率让两个相邻区域具有同样的shadow memory值,虽然概率比较小,但总归是个缺陷。因此工具中会有其他逻辑保证这个前提。
下图展示了HeapOverFlow的检测过程。指针p的标签和访问的地址p[32]所对应的shadow memory值不一致,因此报错(图中只用了4bit记录标记值,但不影响理解,8bit标记值的检测和它一致)。
2.3 优缺点
和ASAN相比,HWASAN具有如下缺点:
- 可移植性较差,只适用于64位机器。
- 需要对Linux Kernel做一些改动以支持工具。
- 对于所有错误的检测将有一定概率false negative(漏掉一些真实的错误),概率为1/256。原因是tag的生成只能从256(2^8)个数中选一个,因此不同地址的tag将有可能相同。
不过相对于这些缺点,HWASAN所拥有的优点更加引人注目:
- 不再需要安全区来检测buffer overflow,既极大地降低了工具对于内存的消耗,也不会出现ASAN中某些overflow检测不到的情况。
- 不再需要隔离区来检测UseAfterFree,因此不会出现ASAN中某些UseAfterFree检测不到的情况。
3. MTE
Memory Tagging是Arm v8.5引入的新的硬件特性,从硬件层面完全实现上述HWASAN的逻辑,并添加相应的汇编指令支持tag的操作和分配等。
https://github.com/google/sanitizers/wiki/Stack-instrumentation-with-ARM-Memory-Tagging-Extension-(MTE)
Reference
- https://www.usenix.org/system/files/conference/atc12/atc12-final39.pdf
- https://arxiv.org/ftp/arxiv/papers/1802/1802.09517.pdf
- https://clang.llvm.org/docs/HardwareAssistedAddressSanitizerDesign.html
- https://github.com/google/sanitizers/blob/master/hwaddress-sanitizer/Hardware%20Memory%20Tagging%20to%20make%20C_C%2B%2B%20memory%20safe(r)%20-%20iSecCon%202018.pdf